A Guide to the Knowledge Based Agent in AI
Discover how a knowledge based agent in AI works. This guide covers core components, architectures like RAG, and real-world business applications.

A knowledge based agent in AI is a smart system that thinks and acts using a built-in library of human-like expertise. Picture it as a digital expert that pairs a specially curated 'brain'—its knowledge base—with a powerful reasoning engine to tackle tricky problems.

What Is a Knowledge Based Agent in AI
Imagine you could hire an expert who has absorbed every textbook, manual, and report ever written on a specific subject. This expert never forgets a thing, can pull up any relevant fact in an instant, and applies pure logic to figure out new challenges. That’s the core idea behind a knowledge based agent. It's a system built to replicate human expertise, but with the incredible speed and scale only a machine can offer.
What sets these agents apart from other types of AI is that they don't just learn from raw data patterns. Instead, they operate on clearly defined information stored in their Knowledge Base (KB)—a structured library of facts, rules, and relationships about a particular field.
The Power of Explicit Knowledge
The real magic kicks in when the agent uses its inference engine to connect the dots. This is its logical reasoning component. It doesn't just fetch facts; it actually deduces new information and makes informed decisions based on what it knows.
For example, if its knowledge base contains the rule "If the printer is offline, check the power cable" and the fact "The power cable is unplugged," the agent can logically infer that plugging the cable in is the solution. Simple, yet powerful.
This approach offers one massive advantage: transparency. Because the agent’s decisions are grounded in clear rules and facts, it can explain how it reached a conclusion. This "explainability" is absolutely vital in fields like medicine or finance, where understanding the 'why' is just as crucial as the 'what'.
A key distinction of a knowledge based agent is its ability to reason from a structured set of facts and rules. This makes its decision-making process transparent and auditable, unlike the 'black box' nature of many machine learning models.
To better understand what makes these agents tick, let's break down their core features.
Key Characteristics of a Knowledge Based Agent
The table below summarises the defining features that distinguish a knowledge based agent from other types of AI.
| Characteristic | Description | Example in Action |
|---|---|---|
| Explicit Knowledge Base | The agent relies on a structured database of facts, rules, and domain-specific information. | A medical diagnostic agent has a KB with symptoms, diseases, and treatment protocols. |
| Inference Engine | It uses a reasoning mechanism to deduce new information and derive conclusions from its KB. | A customer support bot infers a user's subscription tier based on their account ID to provide relevant help. |
| Explainability | The agent can articulate the reasoning behind its decisions by tracing back the rules it used. | A financial advisor agent can show the exact regulations that led to its investment advice. |
| Domain-Specific | It is typically an expert in a narrow, well-defined area rather than a generalist. | An agent designed for IT troubleshooting knows everything about network errors but nothing about baking. |
| Adaptability | Modern agents can update their knowledge base with new information, learning from data and interactions. | An e-commerce bot adds new product return policies to its KB as they are updated by the company. |
These characteristics come together to create a reliable and intelligent system.
From Simple Rules to Dynamic Systems
The earliest knowledge based agents were a bit rigid, often limited by static rules that had to be programmed by hand. Today’s agents are far more dynamic.
They have evolved to learn and adapt, updating their own knowledge bases from new data streams, user conversations, and feedback loops. This evolution neatly bridges the gap between classic, logic-driven AI and modern, data-driven machine learning.
The result is a powerful tool that is both deeply knowledgeable and highly adaptable, forming the bedrock for countless advanced applications—from sophisticated customer support bots to complex diagnostic systems in healthcare. A well-built knowledge based agent doesn't just give answers; it actually solves problems.
A Look Under the Bonnet: The Core Components of an Agent
To really get what makes a knowledge-based AI agent tick, we need to pop the bonnet and look inside. It’s best to think of it not as a single piece of tech, but as a small, highly skilled team. Each member has a specific job, but they all work together seamlessly to get things done.
Every part is vital. Without a solid knowledge base, the agent is just an empty shell. Without its reasoning engine, it's nothing more than a glorified database that can't actually think. Let's break down these crucial pieces one by one.
The Knowledge Base: The Digital Brain
At the absolute centre of any agent is its Knowledge Base (KB). This isn't just a jumble of data; it's a carefully organised library of facts, rules, and relationships about a particular subject. In essence, it’s the agent's digital brain, holding all the expertise it needs to do its job.
For a customer support agent, for example, the KB would be packed with everything from product specifications and troubleshooting guides to return policies and warranty information. This knowledge is structured in a way the agent can easily understand and act upon, often as clear sentences and logical rules.
This explicit, structured approach is what sets a knowledge-based agent apart. The knowledge isn't hidden away in complex mathematical weights like in some other AI models; it's written out clearly, making it transparent and understandable.
The Inference Engine: The Logical Detective
If the Knowledge Base is the library, then the Inference Engine is the sharp-witted detective who pores over the books, connects the dots, and cracks the case. This is the agent's reasoning hub. It takes a user's query, dives into the KB, and uses the facts and rules it finds to deduce new information and figure out the next best step.
The inference engine operates on logical principles. One common technique it might use is called forward chaining, where it starts with the facts it already knows and works its way towards a logical conclusion.
Analogy in Action:
- Fact 1: The customer says their WiFi isn't working.
- Rule in KB: If the WiFi is not working, the first step is to check the router's power light.
- Inference: The agent concludes it needs to ask the user to check the router.
This process lets the agent do more than just fetch and repeat information. It can actually solve problems it hasn't encountered before by applying its existing knowledge in a logical way. This ability to "think on its feet" is what makes a knowledge-based agent so powerful.
The Learning Component: The Ability to Grow
The earliest knowledge-based agents were pretty static. Their knowledge was fixed, and the only way to update it was for a programmer to go in and do it manually. Modern agents are a different breed entirely, thanks to the Learning Component. This gives the agent the power to adapt and get smarter over time by updating its own knowledge base.
This learning can happen in a few different ways:
- From new data: The agent can automatically pull facts and insights from new documents, articles, or data feeds it's given.
- From user interaction: It learns from feedback, paying attention to which of its answers solve problems and which ones miss the mark.
- From observing outcomes: It can see the results of its actions and tweak its internal rules to be more effective next time.
This continuous cycle of improvement means the agent's expertise never goes stale. It evolves right alongside the real world, becoming more accurate and helpful with every single interaction. For instance, in India's education sector, these agents are proving vital in tackling learning gaps among 260 million students. Platforms like BYJU’S and Unacademy use agents with structured pedagogical knowledge bases to create personalised learning paths for over 150 million users. In fact, pilot studies showed that these adaptive systems improved maths proficiency by an incredible 32% among rural students, showcasing the massive impact of a KB that never stops learning. You can discover more insights about this educational transformation.
Sensors and Actuators: Interacting with the World
Finally, an agent isn't much use if it can't interact with the world around it. This is where Sensors and Actuators come into play. You can think of these as the agent's eyes, ears, and hands.
Sensors are the inputs—the tools the agent uses to gather information. For a software agent, a sensor could be a user typing a message into a chatbox or an incoming email landing in an inbox.
Actuators are the outputs—they allow the agent to take action. This could mean sending a reply in a chat, updating a customer's record in a database, or triggering an order in another system.
Think of a support bot one more time. Its sensor is the chat interface where it "sees" your question. Its actuator is that very same interface, where it "types" out its response. Together, these components complete the loop, allowing the agent to perceive, think, and act intelligently in its environment.
Symbolic vs. Hybrid Architectural Designs
Not all knowledge-based AI agents are built the same. The way they're put together on the inside—their architecture—dictates how they think and solve problems. You'll generally find two main approaches: the traditional, rule-bound symbolic design and the more flexible, modern hybrid model.
Choosing between them isn't just a technical footnote; it completely changes what the agent can do. One behaves like a meticulous lawyer, sticking strictly to a pre-written legal code. The other acts like a seasoned researcher, able to consult a massive library to find answers to questions it has never seen before. Let's dig into what that really means.
The Classic Symbolic Architecture
The original knowledge-based agents were built using a Symbolic Architecture. Think of this design as a master of formal logic. It runs on a knowledge base packed with explicit facts and a series of "if-then" rules, all carefully programmed by human experts.
For this kind of agent, the world is black and white. It follows the precise logic it’s been given, no exceptions. A symbolic agent used for medical diagnosis, for instance, might have a rule like, "IF a patient has a fever AND a cough, THEN consider a respiratory infection."
This approach is incredibly reliable for tasks with clear, established rules because you can always trace its logic back to the exact rule that triggered a decision. That transparency is a huge plus. The problem? This strength is also its biggest weakness. Symbolic agents are brittle; they get stuck when faced with ambiguity or any situation not explicitly covered in their rulebook.
The Modern Hybrid Approach
To get around the rigidity of pure symbolic systems, the Hybrid Architecture came along. This approach mixes the structured reasoning of symbolic AI with the incredible pattern-recognition abilities of modern machine learning models. The most popular version of this today is known as Retrieval-Augmented Generation (RAG).
A RAG-based agent is like an expert taking an open-book test. It cleverly combines two core parts:
- A Powerful Language Model (the 'brain'): This is the generative part of the equation, the bit that understands language, reasons through problems, and writes human-like responses.
- An External Knowledge Source (the 'open book'): This is a database or a collection of documents that the model can search—or "retrieve" information from—in real-time.
This two-step process means the agent can ground its answers in factual, up-to-date information, which massively reduces the risk of it just making things up (a big problem known as "hallucination"). It can answer questions about topics it was never explicitly trained on simply by looking up the latest data. This makes the hybrid knowledge-based agent in AI far more adaptable and useful for real-world applications.
The visual below shows how an agent's core components—its knowledge base, inference engine, and learning mechanism—all fit together.
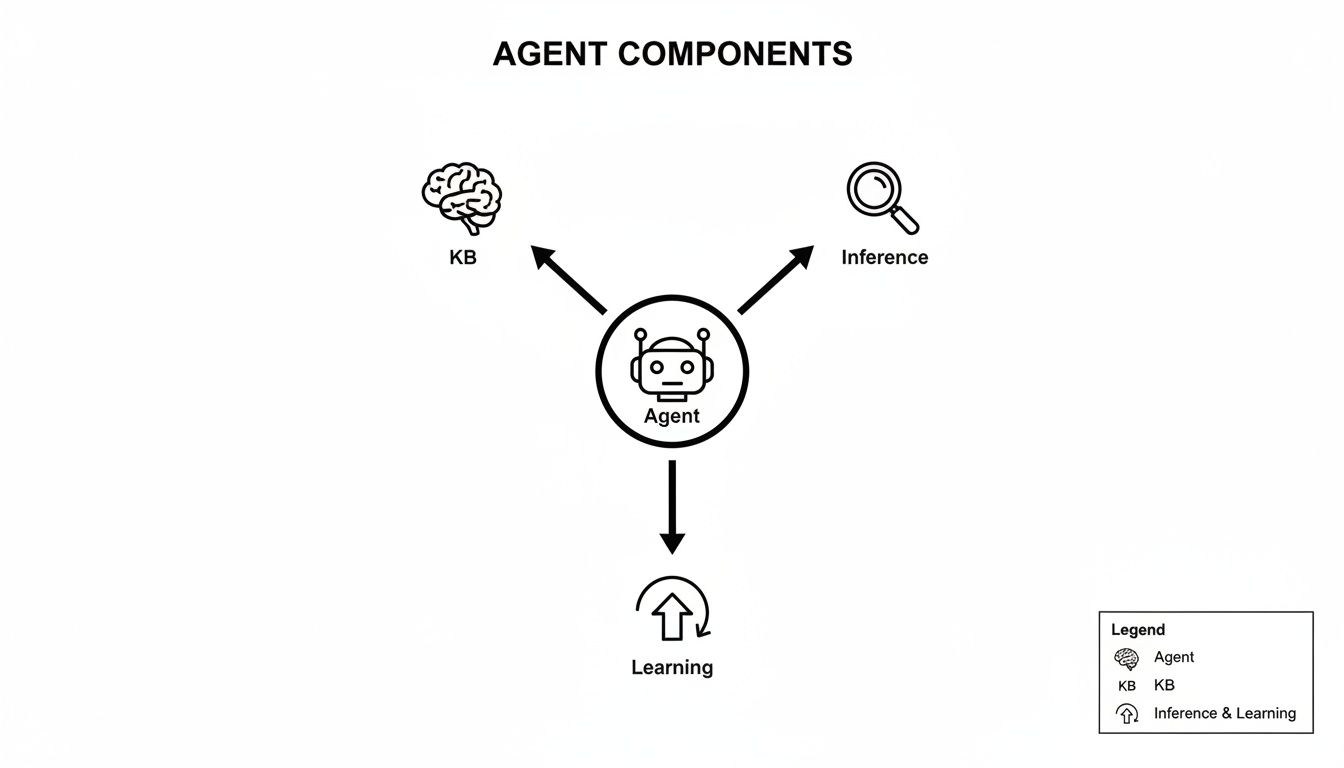
As you can see, the knowledge base is central. It fuels both the agent's reasoning (inference) and its ability to get smarter over time (learning), creating a powerful feedback loop.
Comparing Architectural Designs
So, which one should you choose? It really depends on the job at hand. Each design has its own set of pros and cons that make it a better fit for certain tasks.
A purely symbolic agent offers unmatched precision for rule-based systems, while a hybrid agent provides the flexibility needed for dynamic, real-world conversations and knowledge discovery.
Here’s a side-by-side comparison to make the choice a bit clearer:
| Feature | Symbolic Architecture | Hybrid (RAG) Architecture |
|---|---|---|
| Primary Strength | Precision and explainability | Flexibility and scalability |
| Knowledge Source | Hand-crafted rules and facts | External documents, databases, APIs |
| Best For | Compliance, diagnostics, systems with fixed rules | Customer support, research, dynamic Q&A |
| Key Weakness | Brittle; struggles with ambiguity | Can be complex to set up; relies on retrieval quality |
| Example Use Case | A system that approves or denies loans based on strict financial rules. | A chatbot that answers customer questions using the company's latest help articles. |
Ultimately, for most of today's business challenges—from customer support to internal knowledge management—the hybrid model strikes a much better balance of power and practicality. Platforms like SupportGPT actually specialise in this hybrid approach, making it straightforward for businesses to build agents that are not only intelligent but also consistently accurate by connecting them directly to their own curated knowledge.
Real-World Applications of Knowledge-Based Agents
It's one thing to talk about knowledge-based agents in theory, but where do they actually make a difference? Across India, these systems have moved well beyond the conceptual stage. They're on the ground, solving real problems and adding serious value in industries where precision is non-negotiable.
Their real strength lies in blending vast, specialised knowledge with logical reasoning. Think of them as tireless experts, always on call to provide data-backed insights. This empowers human professionals to make smarter, faster decisions, whether they're in a busy financial centre or a remote health clinic. Let's look at a few places where they're already having a huge impact.

Revolutionising Healthcare Diagnostics
Healthcare is arguably one of the most powerful use cases. Here, a knowledge-based agent can act as a brilliant diagnostic partner.
Picture a doctor faced with a patient presenting a baffling set of symptoms. An AI agent, armed with a knowledge base spanning millions of medical journals, clinical trials, and case studies, can sift through the patient's data in moments. It can suggest potential diagnoses, flag contraindications, and recommend evidence-based treatments—all while clearly explaining its reasoning. This doesn't replace the doctor; it supercharges their expertise, giving them a powerful second opinion to ensure the best possible care.
In India, this is helping to bridge critical gaps in healthcare access. A NITI Aayog report highlights a stark imbalance: over 70% of India's population lives in rural areas, yet only 30% of its doctors work there. To help tackle this, Tamil Nadu's Aravind Eye Care System used knowledge-based agents to analyse retinal scans. The system now processes 2.5 million scans a year, slashing diagnostic time from 20 minutes to less than two. Even better, it has identified 85% more cases of early-stage diabetic retinopathy. You can dive deeper into these AI advancements in this research from Signum.ai.
Streamlining Customer Support
In customer service, nothing beats speed and accuracy. When a customer has a problem, they want it solved now. Knowledge-based agents are completely changing the game by acting as the ultimate support specialists, available 24/7.
These agents are trained on a company’s entire library of information:
- Technical manuals and product specifications
- FAQs and troubleshooting guides
- Histories of past support tickets and their solutions
- Warranty details and return policies
When a customer asks a question, the agent can instantly find the right answer and walk them through a solution. This deflects a massive volume of routine queries, freeing up human agents to handle the truly complex and sensitive issues. The outcome? Customers get faster answers, and the support team becomes far more efficient.
Detecting Fraud in Finance
The financial industry processes a staggering number of transactions daily, which makes it a major target for fraud. A knowledge-based agent is the perfect line of defence because it operates on a strict set of rules and can spot anomalies a human might miss.
Its knowledge base is packed with financial regulations, known fraud patterns, and individual customer transaction histories. The agent monitors financial activity in real-time, applying these rules to flag anything that looks out of place.
For example, if a large transaction comes from a high-risk location at an unusual time of day, the agent can instantly flag it for a human to review. Crucially, it can also explain why it was flagged, making the subsequent investigation much quicker and more effective.
Creating Personalised E-commerce Experiences
Online retail lives and dies by personalisation. A knowledge-based agent can become a dedicated personal shopper for every visitor on a website. By drawing on a knowledge base of product catalogues, customer reviews, and browsing history, it can serve up incredibly relevant recommendations.
Imagine someone is looking for a new laptop. The agent can ask a few simple questions, like, "Will you be using it for gaming, work, or just browsing?" Based on the replies, it consults its knowledge base and suggests models that perfectly fit the user's needs and budget. This turns a generic shopping trip into a helpful, guided experience, which is a proven way to boost sales and build lasting customer loyalty.
How to Build and Implement an Effective Agent
So, how do you actually go about building one of these agents? It might sound like a massive undertaking, but with the right tools and a clear plan, it’s more accessible than you think. Getting a few key stages right is what separates a genuinely helpful agent from a frustrating one.
Let's walk through the practical steps. We'll cover everything from preparing your knowledge base and choosing the right tech, to putting safety measures in place. Focusing on these core pillars will help you build an agent that your customers and internal teams can actually trust.
Selecting and Structuring Your Knowledge Source
Everything starts here. Your knowledge source is the foundation of your agent's intelligence, and if it's shaky, the whole thing falls apart. You can pull from all sorts of places—structured databases, PDFs, help centre articles, or even past support tickets.
Once you’ve picked your sources, you need to get the information ready. This means cleaning out irrelevant details, breaking down long documents into smaller, more focused chunks, and making sure everything is accurate and up to date. The aim is to create a clean, high-quality library of information the agent can draw from with confidence.
A classic mistake is just dumping an entire, unfiltered library of documents on the agent and hoping for the best. The old saying "garbage in, garbage out" has never been more true. A well-curated and properly chunked knowledge base is probably the single biggest factor in an agent's success.
Using Embeddings and Vector Databases
Now you have a clean knowledge source. The next puzzle is, how do you make it understandable to an AI? This is where embeddings and vector databases enter the picture.
Think of an embedding as a translator. It takes a piece of text and converts it into a string of numbers—a vector—that captures its semantic meaning. Sentences with similar meanings end up with similar numerical coordinates in this multi-dimensional space.
These numerical representations are then stored in a special kind of database called a vector database. It’s built specifically for one job: finding the closest matches to a query at incredible speed. When a user asks a question, the agent turns that question into an embedding and queries the database to find the chunks of text from your knowledge source with the most similar meaning.
This is worlds away from old-school keyword searching. Because it understands context, not just matching words, the agent can find the right information even if the user phrases their question in a completely different way.
Implementing Grounding and Guardrails
Building a smart agent isn't just about feeding it information; you also have to set the rules of the road. Two concepts are absolutely critical for making your agent reliable and safe: grounding and guardrails.
Grounding is the process of forcing the agent to base its answers only on the information you've given it in the knowledge source. This is crucial for preventing the model from "hallucinating" or just making things up—a known issue with large language models. Grounding keeps the responses factual and tied directly to your approved content.
Guardrails are the behavioural rules for your agent. They define its personality and ensure it stays professional and on-task. You can set up guardrails to:
- Maintain a specific tone: Make sure the agent always reflects your brand’s voice.
- Prevent off-topic conversations: Keep the agent focused on its job, whether that's support, sales, or something else.
- Handle sensitive topics: Define exactly how the agent should respond to inappropriate or sensitive questions.
- Escalate to a human: Create clear triggers for when a conversation needs to be passed to a person.
Platforms like SupportGPT are designed to make this much simpler. They come with built-in tools that let you ground responses to your specific data and configure robust guardrails without needing a team of AI specialists. This combination of curated knowledge, semantic search, and strict controls is the modern blueprint for building a truly effective and trustworthy knowledge-based agent.
Using Knowledge Agents for Business Intelligence
Forget staring at flashy dashboards and getting lost in dense spreadsheets. A much smarter way of doing business intelligence (BI) is starting to catch on, especially in a fast-paced market like India. Here, a knowledge-based agent in AI is becoming a secret weapon for companies that want to stop just looking at data and start talking to it. The result? Deep, actionable insights, delivered faster than ever before.
Imagine this: instead of waiting for a data analyst to decipher complex charts, a business leader can just ask a question in plain English and get an immediate, data-backed answer. This kind of direct access puts data into everyone's hands, allowing non-technical decision-makers to explore trends, get to grips with customer behaviour, and predict market shifts without needing a crash course in specialised software.
This is a game-changer in sectors like IT and finance, where being a step ahead is everything. An agent can rifle through millions of data points in seconds to answer a question like, "What was the main reason for customer churn last quarter in our tier-2 cities?"
Gaining a Competitive Edge with Smarter Insights
Traditional BI tools are great at showing you what happened. They can spit out reports on sales figures, website traffic, or stock levels without a problem. A knowledge-based agent, on the other hand, is built to help you understand why it happened and what you should do next.
That’s because the agent's knowledge isn't just raw data. It’s enriched with business rules, market context, and historical performance. It has the ability to connect the dots between different sets of data to find insights that would have otherwise stayed buried.
For instance, an agent could analyse sales figures alongside marketing campaign metrics and competitor activity reports. It might conclude that a recent dip in sales wasn't because of a faulty product, but was actually tied to a rival's aggressive discount campaign in a specific region. This is the kind of subtle insight that leads to far smarter, more strategic decisions.
The real power of using a knowledge-based agent for business intelligence lies in its ability to transform data from a passive resource into an active conversational partner, providing nuanced answers that drive strategy.
Real-World Impact in the Indian Market
This technology is already making a real, measurable difference across India. In the country's huge IT sector, these agents are changing how BI gets done. Some e-commerce firms, for example, have boosted their lead conversion rates by as much as 35% by deploying agents trained on market trends and user behaviour. The BFSI sector is seeing similar gains, with one major bank’s agent now fielding 75 million queries every month and helping to slash fraud detection times by 65%. These aren't just small tweaks; they're major leaps forward, as you can see by exploring the full report on knowledge-based agents.
This shift towards conversational BI is making data-driven decisions more accessible and, ultimately, more effective. It marks a huge move away from static reports and towards dynamic, interactive exploration.
For organisations ready to make this leap, powerful tools are already available. Platforms like SupportGPT are specifically designed to help businesses build and train agents on their own unique data, creating a system that can answer complex internal and external questions with precision. By hooking up a powerful AI to a curated knowledge base, companies can essentially build their own expert BI assistants, ready to deliver insights the moment they're needed. It’s an approach that helps teams unlock the true value hiding in their data and build a clear competitive advantage.
Common Questions About Knowledge Based Agents
As we've explored what knowledge-based agents can do, a few key questions tend to pop up. Getting these cleared up is really important for understanding where this technology truly shines and its place in the broader AI ecosystem. Let's dig into some of the most common ones.
What Is the Difference Between a Knowledge Based Agent and a Machine Learning Model?
The easiest way to think about this is to compare an expert with a massive, well-organised library to a talented apprentice who learns by watching. A machine learning model, like that apprentice, learns patterns by sifting through huge amounts of data. It can make surprisingly accurate predictions, but it often works like a 'black box'—it can't really tell you how it came to its conclusion.
A knowledge-based agent, on the other hand, works more like the expert with the library. It operates on a clear set of facts and rules stored in its knowledge base. Because of this, its decisions are logical and transparent; you can literally trace them back to the specific piece of information it used. This is a game-changer in industries where explaining the 'why' behind a decision is non-negotiable. Of course, the most powerful systems today often blend both approaches.
The core difference is explainability. A knowledge-based agent offers transparent, rule-based reasoning, whereas a machine learning model relies on learned, often opaque, data patterns.
How Do You Keep an Agent's Knowledge Base Up to Date?
This is a critical point. An agent is only as good as the information it has access to, so keeping its knowledge current is essential for it to be useful and trustworthy. An outdated knowledge base is a fast track to wrong answers and frustrated users. Luckily, there are a few solid strategies for keeping things fresh.
- Manual Updates: For crucial, slow-moving information like company policies or safety procedures, having human experts directly add, edit, or remove information is the most reliable method.
- Automated Extraction: You can set up systems to automatically scan new documents, websites, or data feeds, pulling out relevant information and adding it to the knowledge base.
- User Feedback Loops: The agent can also learn from its day-to-day interactions. When users mark an answer as helpful or unhelpful, it provides a signal that can flag areas of the knowledge base that need a review.
In modern systems that use Retrieval-Augmented Generation (RAG), this process becomes much simpler. Keeping the agent up-to-date can be as easy as just adding a new document to the folder it reads from.
Are Knowledge Based Agents Difficult to Build?
The answer is: it depends. Building a simple, rule-based agent for a very specific, narrow task can be pretty straightforward. Historically, though, creating a large, dynamic agent involved a ton of effort in a field called "knowledge engineering"—a highly specialised process of designing and populating the knowledge base.
That barrier has come way down. Today, modern platforms and frameworks have made the whole process much more accessible. It's now possible for teams to build incredibly powerful hybrid agents without needing a PhD in artificial intelligence.
Ready to build a reliable AI agent grounded in your own expertise? SupportGPT provides a complete platform to create, manage, and deploy knowledge-based agents that deliver fast, accurate answers. Learn more and get started for free.